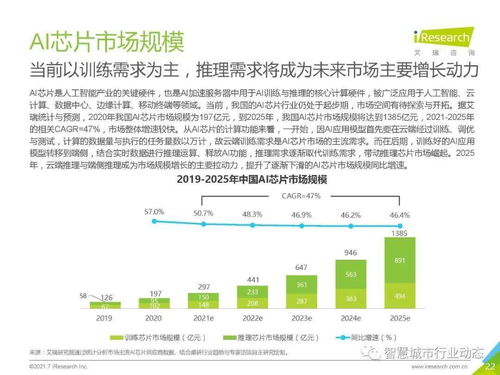
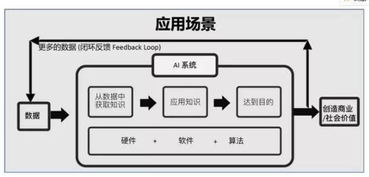
隨著以ChatGPT為代表的大型語(yǔ)言模型(LLM)的崛起,人工智能技術(shù)正以前所未有的速度滲透到各行各業(yè)。從智能對(duì)話到內(nèi)容生成,從代碼輔助到數(shù)據(jù)分析,AI大模型正在重塑軟件開(kāi)發(fā)與應(yīng)用構(gòu)建的方式。本文將系統(tǒng)性地探討AI大模型的應(yīng)用開(kāi)發(fā)、源碼搭建以及人工智能基礎(chǔ)軟件開(kāi)發(fā)的核心路徑。
一、AI大模型:技術(shù)演進(jìn)與應(yīng)用范式
以ChatGPT為例,其背后是GPT(Generative Pre-trained Transformer)系列模型的持續(xù)演進(jìn)。這類(lèi)大模型的核心在于其龐大的參數(shù)規(guī)模(從數(shù)十億到萬(wàn)億級(jí))、海量的預(yù)訓(xùn)練數(shù)據(jù)以及Transformer架構(gòu)的強(qiáng)大能力。它們通過(guò)自監(jiān)督學(xué)習(xí)在海量文本上學(xué)習(xí)語(yǔ)言規(guī)律,再通過(guò)指令微調(diào)(Instruction Tuning)和基于人類(lèi)反饋的強(qiáng)化學(xué)習(xí)(RLHF)等技術(shù),使其能夠理解和遵循人類(lèi)的復(fù)雜指令,生成高質(zhì)量、符合上下文的回應(yīng)。
這種技術(shù)范式開(kāi)啟了“基礎(chǔ)模型(Foundation Model)+ 應(yīng)用適配”的新時(shí)代。開(kāi)發(fā)者無(wú)需再?gòu)牧汩_(kāi)始訓(xùn)練一個(gè)龐大的模型,而是可以基于已有的、強(qiáng)大的預(yù)訓(xùn)練模型,通過(guò)微調(diào)、提示工程(Prompt Engineering)、檢索增強(qiáng)生成(RAG)或API集成等方式,快速構(gòu)建面向特定領(lǐng)域和場(chǎng)景的智能應(yīng)用。
二、大模型應(yīng)用開(kāi)發(fā):核心方法與技術(shù)棧
- API集成與提示工程:對(duì)于絕大多數(shù)應(yīng)用開(kāi)發(fā)者而言,最快捷的方式是直接調(diào)用OpenAI、百度文心、阿里通義等廠商提供的API服務(wù)。核心工作在于設(shè)計(jì)高效的提示詞(Prompt),構(gòu)建清晰的應(yīng)用邏輯,并將大模型的能力無(wú)縫集成到現(xiàn)有系統(tǒng)中。這涉及到對(duì)話管理、上下文處理、輸出解析與后處理等一系列工程問(wèn)題。
- 檢索增強(qiáng)生成(RAG):為解決大模型知識(shí)更新滯后和“幻覺(jué)”問(wèn)題,RAG架構(gòu)成為主流方案。其核心是將外部知識(shí)庫(kù)(如企業(yè)文檔、數(shù)據(jù)庫(kù))通過(guò)向量化技術(shù)構(gòu)建為可檢索的索引。當(dāng)用戶提問(wèn)時(shí),系統(tǒng)先從知識(shí)庫(kù)中檢索相關(guān)信息,再將信息與問(wèn)題一同作為提示輸入給大模型,從而生成基于事實(shí)、準(zhǔn)確可靠的答案。搭建RAG系統(tǒng)需要掌握向量數(shù)據(jù)庫(kù)(如Pinecone、Milvus)、文本嵌入模型(Embedding Model)以及檢索排序算法。
- 模型微調(diào)(Fine-tuning):當(dāng)通用模型在特定任務(wù)上表現(xiàn)不佳,或需要深度定制其行為和風(fēng)格時(shí),就需要對(duì)預(yù)訓(xùn)練模型進(jìn)行微調(diào)。開(kāi)發(fā)者需要準(zhǔn)備高質(zhì)量、結(jié)構(gòu)化的領(lǐng)域數(shù)據(jù)集,使用如LoRA(Low-Rank Adaptation)等參數(shù)高效微調(diào)技術(shù),在保留模型通用能力的讓其精通特定領(lǐng)域。這要求開(kāi)發(fā)者具備一定的機(jī)器學(xué)習(xí)運(yùn)維(MLOps)能力,包括數(shù)據(jù)管理、訓(xùn)練流程、模型評(píng)估與部署。
- 智能體(Agent)架構(gòu):這是更前沿的應(yīng)用形態(tài)。智能體將大模型作為“大腦”,賦予其調(diào)用工具(如搜索、計(jì)算、執(zhí)行代碼)、記憶和規(guī)劃的能力。通過(guò)ReAct等框架,智能體可以自主拆解復(fù)雜任務(wù),逐步執(zhí)行,實(shí)現(xiàn)更高程度的自動(dòng)化。開(kāi)發(fā)智能體需要設(shè)計(jì)精良的任務(wù)規(guī)劃、工具調(diào)用和狀態(tài)管理邏輯。
三、源碼搭建與自主部署:從開(kāi)源模型出發(fā)
對(duì)于希望擁有更高自主性、控制數(shù)據(jù)隱私或進(jìn)行深度定制的團(tuán)隊(duì),基于開(kāi)源大模型進(jìn)行源碼搭建是必然選擇。
- 模型選擇:開(kāi)源生態(tài)已非常繁榮,涌現(xiàn)出如Meta的Llama系列、清華的ChatGLM、百川智能的Baichuan、阿里的Qwen等優(yōu)秀模型。開(kāi)發(fā)者需根據(jù)應(yīng)用場(chǎng)景(中/英文、代碼、推理)、硬件資源(顯存大小)和性能要求選擇合適的模型及參數(shù)量級(jí)(如7B、13B、70B)。
- 環(huán)境搭建與部署:
- 硬件:通常需要配備高性能GPU(如NVIDIA A100/H100,或消費(fèi)級(jí)的RTX 4090等)的服務(wù)器。
- 軟件棧:核心包括深度學(xué)習(xí)框架(如PyTorch)、模型加速庫(kù)(如vLLM、TGI - Text Generation Inference)、CUDA驅(qū)動(dòng)等。
- 部署框架:使用FastAPI、Gradio、Streamlit等快速構(gòu)建Web API或交互界面。利用Docker容器化技術(shù)保證環(huán)境一致性。
- 推理優(yōu)化:為了在有限資源下實(shí)現(xiàn)低延遲、高并發(fā)的服務(wù),需要應(yīng)用模型量化(Quantization,如GPTQ、AWQ)、模型剪枝、注意力機(jī)制優(yōu)化(如FlashAttention)等技術(shù),大幅降低模型運(yùn)行所需的顯存和計(jì)算量。
- 系統(tǒng)工程:構(gòu)建生產(chǎn)級(jí)系統(tǒng)還需考慮負(fù)載均衡、自動(dòng)擴(kuò)縮容、請(qǐng)求隊(duì)列、監(jiān)控告警、日志記錄、成本控制等完整的后端工程能力。
四、人工智能基礎(chǔ)軟件開(kāi)發(fā):構(gòu)建更底層的AI能力
大模型應(yīng)用之上,是更底層的人工智能基礎(chǔ)軟件,它們構(gòu)成了AI開(kāi)發(fā)的“基礎(chǔ)設(shè)施”。
- 深度學(xué)習(xí)框架:如PyTorch、TensorFlow、JAX,是構(gòu)建和訓(xùn)練神經(jīng)網(wǎng)絡(luò)的基石。理解其自動(dòng)微分、張量計(jì)算和分布式訓(xùn)練機(jī)制是進(jìn)行底層算法創(chuàng)新的前提。
- 模型訓(xùn)練與優(yōu)化庫(kù):如Hugging Face的Transformers、Accelerate,DeepSpeed(微軟), Megatron-LM(NVIDIA)等,提供了預(yù)訓(xùn)練模型、高效訓(xùn)練策略(如混合精度訓(xùn)練、ZeRO優(yōu)化)和便捷的微調(diào)接口。
- 向量數(shù)據(jù)庫(kù)與檢索系統(tǒng):專(zhuān)門(mén)為存儲(chǔ)和查詢(xún)高維向量(嵌入)而設(shè)計(jì),是RAG系統(tǒng)的核心組件。理解其索引結(jié)構(gòu)(如HNSW)、相似度度量算法和分布式設(shè)計(jì)至關(guān)重要。
- 機(jī)器學(xué)習(xí)運(yùn)維(MLOps)平臺(tái):涵蓋從數(shù)據(jù)管理、特征工程、模型訓(xùn)練、評(píng)估、版本管理到部署、監(jiān)控的全生命周期管理。開(kāi)發(fā)或使用如MLflow、Kubeflow等平臺(tái),能極大提升AI項(xiàng)目的工程化水平和迭代效率。
五、挑戰(zhàn)與未來(lái)展望
盡管前景廣闊,但開(kāi)發(fā)之路仍充滿挑戰(zhàn):高昂的算力成本、模型“幻覺(jué)”的治理、數(shù)據(jù)安全與隱私保護(hù)、提示詞的脆弱性、評(píng)估體系的缺失等。技術(shù)將向多模態(tài)、小型化、專(zhuān)業(yè)化、智能體化方向發(fā)展。對(duì)開(kāi)發(fā)者而言,既要深入理解大模型的原理與局限,又要掌握扎實(shí)的軟件工程和系統(tǒng)架構(gòu)能力,同時(shí)具備良好的提示設(shè)計(jì)、數(shù)據(jù)構(gòu)造和評(píng)估思維,方能在這波AI浪潮中構(gòu)建出真正可靠、有價(jià)值的產(chǎn)品。
總而言之,從調(diào)用API到微調(diào)開(kāi)源模型,再到參與基礎(chǔ)軟件建設(shè),AI大模型應(yīng)用開(kāi)發(fā)是一個(gè)多層次、多技能要求的領(lǐng)域。它不僅是提示詞的藝術(shù),更是數(shù)據(jù)、算法、軟件工程和領(lǐng)域知識(shí)的深度融合。